An end-to-end cloud application may utilize a large variety of cloud services and technologies. Cloud applications can be built with different architectures, but in general they can be divided into the following tiers:
- Client side - applications that run on various devices and connect to the cloud.
- Networking - access to cloud and communication with and between services.
- Compute - the infrastructure and platforms that enable the execution of cloud services.
- Data storage - the ability to store, manage, organize, query and retrieve persistent data.
The following diagram describes these tiers:
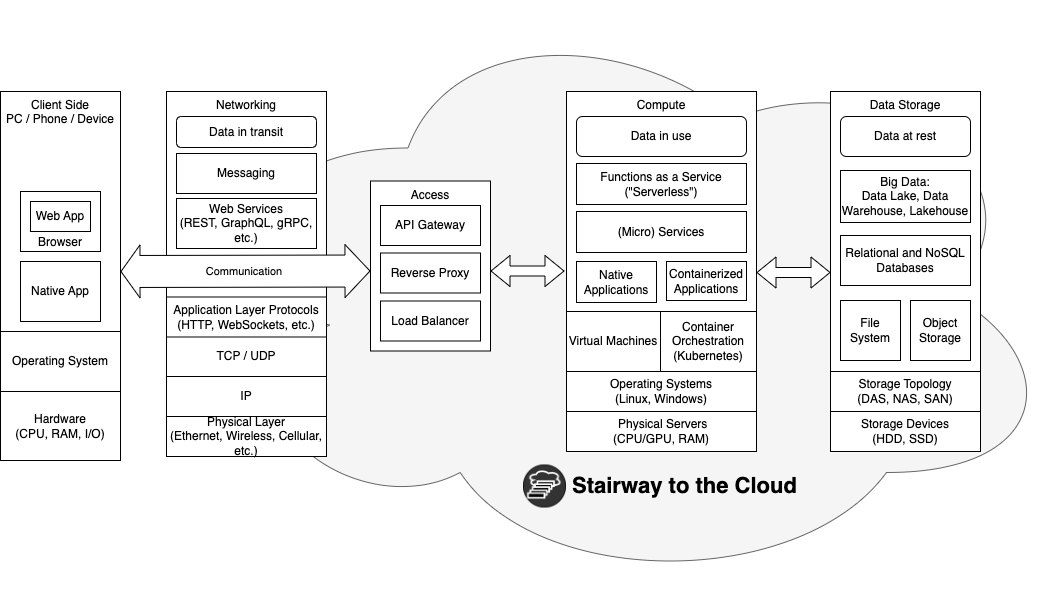
The cloud stack
Client Side
The client side of a cloud application operates independently from the cloud infrastructure. It can have a user interface which interacts with the end-user (front end), a backend service or a Machine-to-Machine (M2M) application. Such clients can be run on top of various platforms such as: Web applications running inside Web browsers, Desktop applications running on PCs, Mobile applications running on mobile devices and Embedded applications running on various devices (IoT). Applications are running on top of the operating system of the device, which controls its hardware, including CPU, memory and I/O.
Networking
Every device that needs to access the cloud must have the ability to connect to the network. This can be done over various “last mile” bearers such as Ethernet, Fiber, Wifi and Cellular. Eventually once they reach their Internet Service Provider (ISP), communication is routed through the Internet backbone to its destination. Routing is handled by the Internet Protocol (IP) where each message has a destination IP address.
The communication stack is built on top of the Internet protocol suite, commonly known as TCP/IP. Application layer protocols that run on top of TCP/IP, provide end-to-end communication between different computational applications and their components. The most common application layer protocol is The Hypertext Transfer Protocol (HTTP). It is a communication protocol for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web (WWW). The majority of the communication on the web happens over HTTP, which is not only used for Web browsing, but also as the underlying communication protocol for Web Services that expose the APIs of cloud services. Web Services such as REST, GraphQL and gRPC are based on a synchronous request-response model. Another communication method is asynchronous messaging, where the sending party can send a message and continue with its unrelated tasks without waiting for an immediate response from the receiving party. This model is also used for ingesting high-volume, real-time event streams into the cloud. Data in transit which is sent over any communication method, is serialized using various formats such as HTML, XML, JSON and Protobuf.
In the access tier of the cloud, incoming traffic is managed by Application Delivery Controllers (ADCs), such as Load Balancer, Reverse Proxy and API Gateway. ADCs are located at the edge of the cloud and handle a wide variety of functions, which play crucial roles in managing, scaling, optimizing and securing communication between clients and servers.
Compute
The compute tier is the core of the cloud. It is based on the cloud processing power which enables the execution of software applications as cloud services. In the lowest level we can find the physical servers. These are powerful computers that are located in a data center of a cloud provider. The hardware of each server obviously includes a CPU with multiple cores and/or a GPU. It also has some amount of RAM and network connectivity through a Network Interface Card (NIC).
The server’s hardware, like any other modern computer, is managed by an Operating System (OS). It provides common services and functionalities that allow software programs to run on the underlying machine. In the cloud, we would typically find Linux (in different flavors) and Windows operating systems. Although some cloud providers allow users to rent dedicated machines with access to the native OS (“bare metal”), in most cases cloud computing is based on virtualization, which is enabled by hypervisors. It allows the cloud provider to share physical machines between different customers and utilize them in an optimal manner. It is based on the creation of Virtual Machines (VMs) that act like real computers with operating systems. Each physical server can have many virtual machines running on the same machine.
Native applications are deployed on top of physical or virtual machines. These applications are installed directly on top of the host OS. However in recent years, Containers – and more specifically, containerized microservices or “serverless” Functions as a Service (FaaS) – have become the de-facto compute standard of modern cloud-native applications. Containers are a method of packaging and isolating applications into standardized units that can be easily moved between environments. They include all the dependencies that an application might need to run on any host operating system, such as libraries, binaries, configuration files, and frameworks, into a single lightweight executable.
In small numbers, containers are easy enough to deploy and manage manually. But as application architectures become more complex and the number of containers needed to maintain stability across a distributed system grows, managing them at scale is impossible without automation. This is where container orchestration comes into play. Container Orchestration tools such as Kubernetes, automates the deployment, management, scaling, and networking of containers.
Data Storage
The data tier is where “data at rest” is stored in a persistent manner. The lower level includes physical storage devices such as Hard Disk Drives (HDDs) and Solid State Drives (SDDs). Storage devices can be connected to servers directly as Direct Attached Storage (DAS). But most of the cloud storage is accessed through the network either by using Network Attached Storage (NAS) or Storage Area Network (SAN) topologies. Cloud storage in general, does not refer to a specific technology or topology. It is a cloud computing model that enables storing data and files on the Internet through a cloud provider that can be accessed either through the public internet or a dedicated private network connection.
Files, blocks, and objects are storage formats that hold, organize, and present data in different models — each with their own capabilities and limitations. But while file and block storage are accessed through a file system, object storage is actually a web service that is accessed through a proprietary API (usually S3 compliant). File systems and object storage enable basic data storage, but they lack the ability to efficiently find, retrieve and update specific data items within files or objects. For that we use databases (DBs), which are structured collections of data. The data is typically organized in a specific way, such as by columns and rows in a table, and can be searched, sorted, and retrieved efficiently. Relational (SQL) and non-relational (NoSQL) DBs are two types of database systems commonly implemented in cloud-native apps. Relational databases provide a highly consistent store of related data tables, while NoSQL databases refer to high-performance, non-relational data stores in various models such as key-value, documents and Graph.
Some data sets are too large or complex to be dealt with by traditional data management systems. Big data requires innovative storage solutions that can handle its volume, velocity and variety. Such solutions are Data Warehouse, which can handle large volumes of structured data and Data Lake, which allows raw data to be stored in its native format until needed. These two solutions have begun to merge into the converged concept of data lakehouse.