Big data primarily refers to data sets that are too large or complex to be dealt with by traditional data management systems. It includes diverse collections of structured, unstructured and semi-structured data that continues to grow exponentially over time. Though used sometimes loosely partly due to a lack of formal definition, the best interpretation is that it is a large body of information that cannot be comprehended when used in small amounts only.
Big data analysis challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying and updating. Big data was originally associated with three key concepts (also known as the three Vs):
- Volume - Big data requires processing high volumes of low-density, unstructured data. The size of the data determines the value and potential insight, and whether it can be considered big data or not. For some organizations, this might be tens of terabytes of data. For others, it may be hundreds of petabytes.
- Velocity - Big data is generated, received and processed at a fast rate. It is often produced in (near) real time, and therefore, it must also be processed, accessed, and analyzed at the same rate to have any meaningful impact.
- Variety - With the rise of big data, data comes in new unstructured data types that no longer fit neatly in relational databases. Big data is heterogeneous, meaning it can come from many different sources and can be structured, unstructured, or semi-structured.
Big data technologies evolved with the prime intention to capture, store, and process the semi-structured and unstructured (variety) data generated with high speed (velocity), and huge in size (volume). In addition to these three original Vs, three others that are often mentioned in relation to harnessing the power of big data:
- Veracity - The truthfulness or reliability of the data, which refers to the data quality and the data value. Large datasets can be unwieldy and confusing, while smaller datasets could present an incomplete picture. The higher the veracity of the data, the more trustworthy it is.
- Variability - The characteristic of the changing formats, structure, or sources of big data. Big data analysis may integrate raw data from multiple sources. The processing of raw data may also involve transformations of unstructured data to structured data.
- Value - It’s essential to determine the business value of the data that is collected. Big data must contain the right data and then be effectively analyzed in order to yield insights that can help drive decision-making. Value may also represent the profitability of information that is retrieved from this analysis.
Big Data Architecture
A big data architecture is designed to handle the ingestion, processing, and analysis of large data sets. It enables storing and processing data in volumes that are too large for traditional database systems. Big data tools transform unstructured data for analysis and reporting. Additional tools capture, process, and analyze unbounded streams of data in real time, or with low latency.
Big data solutions typically involve one or more of the following types of workload:
- Batch processing of big data sources at rest.
- Real-time processing of big data in motion.
- Interactive exploration of big data.
- Predictive analytics and machine learning.
Most big data architectures include some or all of the following components
- Data Sources - All big data solutions start with one or more data sources. Examples include:
- Application data stores, such as relational databases.
- Static files produced by applications, such as web server log files.
- Real-time data sources, such as IoT devices.
- Data Storage - Data for batch processing operations is typically stored in a distributed file store that can hold high volumes of large files in various formats. This kind of store is often called a data lake.
- Batch Processing - Because the data sets are so large, often a big data solution must process data files using long-running batch jobs to filter, aggregate, and prepare the data for analysis. MapReduce is a very popular way of running these batch jobs on distributed data.
- Real-time Message Ingestion - If the solution includes real-time sources, the architecture must include a way to capture and store real-time messages for stream processing. This portion of a streaming architecture is often referred to as stream buffering, which can be implemented with event streaming solutions such as Apache Kafka.
- Stream Processing - After capturing real-time messages, the solution must process them by filtering, aggregating, and otherwise preparing the data for analysis. Apache Storm is a popular open source technology that can handle stream processing.
- Machine learning - Reading the prepared data for analysis (from batch or stream processing), machine learning algorithms can be used to build models that can predict outcomes or classify data. These models can be trained on large datasets, and the resulting models can be used to analyze new data and make predictions.
- Analytical Data Store - Many big data solutions prepare data for analysis and then serve the processed data in a structured format that can be queried using analytical tools. This can be done with a relational data warehouse (commonly used for BI solutions) or through NoSQL technology like HBase or Hive.
- Orchestration - Big data solutions consist of repeated data processing operations that transform source data, move data between multiple sources and sinks, load the processed data into an analytical data store, or push the results straight to a report or dashboard. Apache Oozie can be used to orchestrate these jobs.
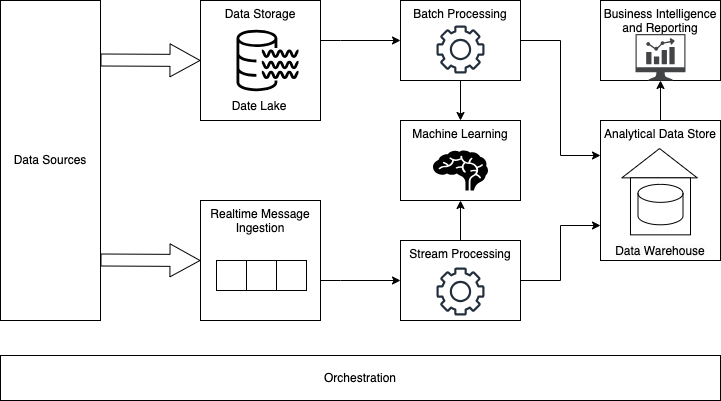
Big Data architecture
Big Data Storage
The challenges of big data have pushed data storage solutions to evolve into more scalable, flexible, and efficient systems. These systems are based on a compute and storage architecture that can be used to collect and manage huge-scale datasets and perform real-time data analyses. These analyses can then be used to generate intelligence from metadata.
Data Warehouse
A data warehouse is a unified data repository for storing large amounts of information from multiple sources within an organization. A data warehouse represents a single source of data truth in an organization and serves as a core reporting and business analytics component.
Typically, data warehouses store historical data by combining relational data sets from multiple sources, including application, business and transactional data. The raw data is transformed and cleaned before loading it into the warehousing system. Organizations invest in data warehouses because of their ability to quickly deliver business insights from across the organization. The benefit of having all of a company’s data in one place is being able to run analytics on the entirety of a company’s data while centralizing security, compliance, and governance in one place.
Data warehouses enable business analysts, data engineers, and decision-makers to access data via BI tools, SQL clients, and other less advanced (i.e., non-data science) analytics applications. They are often the most sensible choice for data platforms whose primary use case is for data analysis and reporting. With pre-built functionalities and robust SQL support, data warehouses are tailor-made to enable swift, actionable querying for data analytics teams working primarily with structured data.
Data Lake
A data lake is a centralized, highly flexible and low-cost storage repository that stores large amounts of structured and unstructured data in its raw, original, and unformatted form. In contrast to data warehouses, which store already “cleaned” relational data, a data lake stores data using a flat architecture and object storage in its raw form. Data lakes are flexible, durable, and cost-effective and enable organizations to gain advanced insight from unstructured data in its native format, unlike data warehouses that struggle with data in this format.
In data lakes, the schema or data is not defined when data is captured; instead, data is extracted, loaded, and transformed (ELT) for analysis purposes. Data lakes serve as a foundation for various processing and analytics tasks. Data lakes allow for machine learning and predictive analytics using tools for various data types from IoT devices, social media and streaming data.
Traditionally, data lakes have been created by combining various technologies. For metadata organization, they often use Hive, AWS Glue, or Databricks. Storage can utilize S3, Google Cloud Storage, Microsoft Azure Blob Storage or Hadoop HDFS. Compute tasks might run on Apache Pig, Hive, Presto, or Spark. Commonly, data formats such as JSON, Apache Parquet, and Apache Avro are used in these environments. Data lakes also typically decouple storage and compute, which can enable cost savings while facilitating real-time streaming and querying. They also encourage distributed computation for enhanced query performance and parallel data processing.
Data Lakehouse
A data lakehouse is a new, big-data storage architecture that combines the best features of both data warehouses and data lakes. It is a storage technology that combines the scalability and flexibility of a data lake with the structure and reliability of a data warehouse. It brings the best of both worlds together to provide a unified platform for storing, processing, and analyzing data. A data lakehouse enables a single repository for all data types (structured, semi-structured, and unstructured) while enabling best-in-class machine learning, business intelligence, and streaming capabilities.
In lakehouse data storage, raw source data is stored in a data lake. The lakehouse has built-in data warehouse elements, like schema enforcement and indexing, which data teams can use to transform data for analysis, maintain data integrity, and simplify governance. Organizations can implement data quality processes to ensure data accuracy and reliability, including data profiling, cleansing, validation, and metadata management.
The inception of the data lakehouse came about as cloud warehouse providers began adding features ordinarily associated with lakes, as seen in platforms like Amazon Redshift Spectrum and Delta Lake. Conversely, data lakes began incorporating warehouse-like features, such as including SQL functionality and schema definitions. Some data lakehouses developed their own query engine, while others use an open-source query engine like Trino or Presto. For heavy compute-intensive workloads like machine learning, Spark is typically used as the processing engine. This innovation creates the possibility for data lakes to serve analysis and exploration directly, eliminating the need for summarization into traditional data warehouses.
File formats like Parquet have introduced more stringent schema to data lake tables, alongside a columnar format for improved query efficiency. To further bridge the gap, technologies like Delta Lake and Apache Hudi have brought greater reliability in write/read transactions to data lakes. This nudges them closer to the prized ACID characteristics that are intrinsic to conventional database technologies.
Big Data Processing
ETL
Extract, Transform, Load (ETL) is a three-phase data integration process where data is extracted, transformed (cleaned, sanitized, scrubbed) and loaded into a target data store. ETL pipelines combine data from multiple sources into a large, central repository which is typically a data warehouse. ETL uses a set of business rules to clean and organize raw data and prepare it for storage, data analytics, and machine learning (ML). ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.
ELT
ELT has the same operations as ETL but in a different order. ELT copies or exports the data from the source locations, but instead of loading it to a staging area for transformation, it loads the raw data directly to the target data store to be transformed as needed. ELT is particularly useful for high-volume, unstructured datasets as loading can occur directly from the source. ELT can be more ideal for big data management since it doesn’t need much upfront planning for data extraction and storage.
MapReduce
MapReduce is a big data analysis model that processes data sets using a parallel, distributed algorithm on computer clusters, typically Apache Hadoop clusters or cloud systems like Amazon Elastic MapReduce (EMR) clusters. A MapReduce model is composed of a map procedure, which performs filtering and sorting, and a reduce method, which performs a summary operation. With MapReduce, rather than sending data to where the application or logic resides, the logic is executed on the server where the data already resides, to expedite processing. Data access and storage is disk-based, which means that the input is usually stored as files containing structured, semi-structured, or unstructured data, and the output is also stored in files.