A database (DB) is a structured collection of data, which is stored and accessed electronically in a computer system. The data is typically organized in a specific way, such as by columns and rows in a table, and can be searched, sorted, and retrieved efficiently. A database is usually controlled by a database management system (DBMS). The DBMS manages dedicated files on the computer’s disk and presents a logical interface for users and applications. Together, the data and the DBMS, along with the applications that are associated with them, are referred to as a database system, often shortened to just a database.
Database management systems are typically designed to organize data according to a specific pattern. These patterns, called database types or database models, are the logical and structural foundations that determine how individual pieces of data are stored and managed. There are several different types of databases, including relational DBs and non-relational (NoSQL) DBs. Each type has its own characteristics and is designed to meet different needs.
Database Storage
Most databases rely on disk storage to keep their data persistent, meaning that the data is reliably saved for later, even if the database application or the computer itself restarts. In contrast, some databases use ephemeral (volatile) in-memory storage. Ephemeral storage does not survive application or system shutdown or reboot. The advantage of in-memory databases is that they are typically very fast. In practice, many environments will use a mixture of both of these types of systems to gain the advantages of each type. For systems that accept new writes to the ephemeral layer, this can be accomplished by periodically saving ephemeral data to disk. Other systems use read-only in-memory copies of persistent data (i.e. cache) to speed up read access. These systems can reload the data from the backing storage at any time to refresh their data.
Databases provide a set of guarantees around how this data is stored and retrieved, such as:
- Durability – guarantees that data is not lost if the DBMS crashes
- Consistency – After data is written, will all subsequent reads always give the most recent value of the data? (this is important for distributed databases)
- Read/Write Speeds – IOPS is the standard measure of input and output operations per second on storage devices.
Database Schema
In databases that operate on well-defined structured data like relational databases, the shape of the data structure and its constraints are often known as the database’s schema. A database schema is a strict outline of how data must be formatted to be accepted by a particular database. This covers the specific fields that must be present in individual records as well as requirements for values such as data type, field length, minimum or maximum values, etc.
DBMS that value flexibility over regularity are often referred to as schema-less databases, which are typically Not-only-SQL (NoSQL) DBs. While this seems to imply that the data stored within these databases has no structure, this is usually not the case. Instead, the database’s structure is determined by the data itself and the application’s knowledge of and relation to the data. The database usually still adheres to a structure, but the DBMS is less involved in enforcing the constraints.
Database Interface
While the database system takes care of how to store the data on disk or in-memory, it also provides an interface for users or applications. The interfaces for the DB must be able to represent the operations that external parties can perform and must be able to represent all of the data types that the system supports.
Databases typically allow the following four types of interactions:
- Data definition: Create, modify, and remove definitions of the data’s structure (often known as the database’s schema). These operations change the properties that affect how the database will accept and store data. This is more important in some types of databases than others.
- Update: Insert, modify, and delete data within the database. These operations change the actual data that is being managed.
- Retrieval: Provide access to the stored data. Data can be retrieved as-is or can often be filtered or transformed to massage it into a more useful format. Many database systems understand rich querying languages to achieve this (e.g., SQL).
- Administration: Other tasks like user management, security, performance monitoring, etc. that are necessary but not directly related to the data itself.
A database query is a formatted command used to make a request to access data from a DB, to manipulate it, or retrieve it. The syntax is based on some query language and it is associated with some sort of CRUD (create, read, update, delete) function, as well as more advanced functions like filtering, counting and summing. The database system processes the query to understand what actions to take and what data to return to the client.
SQL
Structured Query Language (SQL) is the most common, popular and standardized query language. SQL is designed for managing data held in a relational DB but can also be used for querying non-relational DBs. It is perfect for complex data structures and queries. Many records can be accessed with a single SQL query, but the performance of queries depends on the indexing of records. A database index is a structure that is created to allow for faster record finding within a table. It maps search keys to corresponding data on disk by using different in-memory & on-disk data structures. Queries that target the indexed columns can identify applicable rows in the table quickly by using a more efficient lookup strategy than checking each row line by line (full table scan).
Database Consistency and Availability
The CAP Theorem
The CAP Theorem (introduced by Professor Eric A. Brewer) refers to three characteristics of distributed data stores:
- Consistency – Every read operation returns the latest write operation or an error.
- Availability – Every request receives a non-error response, without the guarantee that it contains the latest write.
- Partition tolerance – The system continues to operate despite network failures (e.g., dropped partitions, slow network connections, or unavailable network connections between nodes).
The CAP theorem states that in a distributed data store system, it is impossible to simultaneously guarantee all the above three properties. This theorem has important implications for the design of distributed systems, particularly when it comes to choosing between consistency and availability in the face of network failures. It places an ultimate upper bound on what can possibly be accomplished by a distributed system. Brewer argues that a system can be both available and consistent in normal operation, but in the presence of a system partition, this is not possible: If the system continues to work in spite of the partition, there is some non-failing node that has lost contact to the other nodes and thus has to decide to either continue processing client requests to preserve availability (AP, eventual consistent systems) or to reject client requests in order to uphold consistency guarantees (CP). The first option violates consistency, because it might lead to stale reads and conflicting writes, while the second option obviously sacrifices availability.
Database Consistency Models
Some databases are built to guarantee strong consistency (ACID) while others favor availability (BASE).
ACID
The ACID database transaction model ensures that a performed transaction is always consistent. ACID stands for:
- Atomic – Each transaction is either properly carried out or the process halts and the database reverts back to the state before the transaction started. This ensures that all data in the database is valid (“all or nothing”).
- Consistent – A processed transaction will never endanger the structural integrity of the database. Any data written by a transaction must be valid according to all defined rules and maintain the database in a good state.
- Isolated – Transactions cannot compromise the integrity of other transactions by interacting with them while they are still in progress.
- Durable – The data related to the completed transaction will persist even in the cases of network or power outages. If a transaction fails, it will not impact the manipulated data.
Relational Database Management Systems (RDBMS), also known as SQL databases, provide ACID compliance. This makes them a good fit for applications which deal with online transaction processing (e.g., financial applications) or online analytical processing (e.g., data warehouses).
While ACID is a building block of relational DBs, many NoSQL DBs are built as distributed systems, and they can’t always ensure complete transactional consistency. As indicated by the CAP theorem, such databases need to choose between full consistency and full availability. Therefore, BASE was introduced as a loose version of ACID characteristics.
BASE
BASE stands for:
- Basically Available – Rather than enforcing immediate consistency, BASE-modeled NoSQL databases will ensure availability of data by spreading and replicating it across the nodes of the database cluster.
- Soft State – Due to the lack of immediate consistency, data values may change over time. The BASE model breaks off with the concept of a database which enforces its own consistency, delegating that responsibility to developers.
- Eventually Consistent – The fact that BASE does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads are still possible (even though they might not reflect the reality).
BASE provides several advantages over ACID compliant databases which are distributed systems by design and cannot guarantee safety from network failures. BASE properties allow NoSQL databases to be distributed in nature and provide high scalability, fast read-write performance, easy replication and big data analytics capability.
Database Types
Database types, sometimes referred to as database models or database families, are the patterns and structures used to organize data within a DBMS. Many different database types have been developed over the years. Modern databases are roughly divided into two major paradigms: relational (SQL) databases and non-relational (NoSQL) databases. The following table summarizes the five main differences between relational and non-relational databases:
| Relational DBs | Non-Relational (NoSQL) DBs | |
|---|---|---|
| Data model | Tables with rows and columns | Various models: key-values, documents, columns, graph |
| Data schema | Strict, rigid and predefined schema | Schemaless (flexible schema may be applied by the application) |
| Query language | SQL | Proprietary |
| Consistency model | ACID | BASE |
| Scalability | Mostly vertical (horizontal can be achieved by sharding) | Horizontal (simply by adding servers to the cluster) |
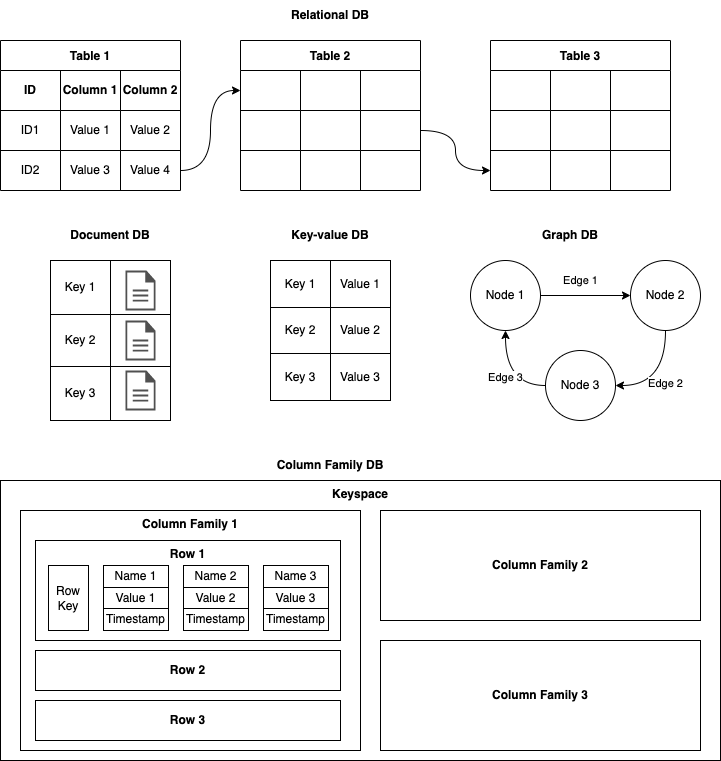
Database types
Relational Databases
Relational databases are the oldest general purpose database type still widely used today. In fact, relational databases comprise the majority of databases currently used in production. Relational databases organize data using tables (or “relations”) of columns (or fields) and rows (or records). Tables are structures that impose a schema on the records that they hold. Each column within a table has a name and a data type. Each row represents an individual record or data item within the table, which contains values for each of the columns. Each row in a table could be marked with a unique identifier called a primary key, and rows among multiple tables can be made related using foreign keys. This allows the data to be structured across multiple tables, which can be joined together via a primary key or a foreign key. These unique identifiers demonstrate the different relationships which exist between tables. Relational databases offer various indexing techniques and query optimization strategies, which help improve query performance and reduce resource consumption.
Relational DBs are typically provisioned to a single server and scale vertically by adding more resources to the machine. Many RDBMS support built-in replication features where copies of the primary database can be made to other secondary server instances. Write operations are made to the primary instance and replicated to each of the secondaries. Upon a failure, the primary instance can fail over to a secondary to provide high availability. Secondaries can also be used to distribute read operations. While writes operations always go against the primary replica, read operations can be routed to any of the secondaries to reduce system load. Data can also be horizontally partitioned across multiple nodes, such as with sharding.
Many of the most widely used databases are relational, such as Oracle, MySQL, SQL Server, PostgreSQL, MariaDB and IBM Db2.
Non-Relational Databases
Non-relational databaes are often called NoSQL, which means “not only SQL”. A NoSQL database enables the storage and querying of data outside the traditional structures found in relational databases, using any of these primary data models:
Key-Value Databases
Key-value databases, or key-value stores, are one of the simplest database types. Key-value stores work by storing arbitrary data accessible through unique keys. In most basic implementations, the database does not evaluate the data it is storing and allows limited ways of interacting with it. Pure key-value stores do not support operations beyond simple CRUD. Some implementations provide more complex actions on top of this foundation according to the basic data type stored under each key. For instance, they might be able to increment numeric values or perform slices or other operations on lists. Since many key-value stores load their entire datasets into memory, these operations can be completed very efficiently.
Key-value stores don’t prescribe any schema for the data they store, and as such, are often used to store many different types of data at the same time. The user is responsible for defining any naming scheme for the keys that will help identify the values and are responsible for ensuring the value is of the appropriate type and format. Key-value storage is most useful as a lightweight solution for storing simple values that can be operated on externally after retrieval.
Many of the key-value stores are implemented as in-memory cache solutions, such as Redis and Memcached. There are also persistent key-value databases such as Amazon DynamoDB and etcd.
Document Databases
Document databases, also known as document-oriented databases or document stores, share the basic access and retrieval semantics of key-value stores. A document store is a key-value store that restricts values to semi-structured formats such as XML, JSON or BSON. These values are referred to as documents. Each document is effectively an object containing attribute metadata along with a typed value such as string, date, binary or an array. This provides a way to index and query data based on the attributes in the document. It is not only possible to fetch an entire document by its ID, but also to retrieve only parts of a document, e.g. the age of a customer, and to execute queries like aggregation, query-by-example or even full-text search. So, unlike with key-value stores, the content stored in document databases can be queried and analyzed.
Though the data within documents is organized within a structure, document databases do not prescribe any specific format or schema. Each document can have a different internal structure that the database interprets. Groups of documents are called collections, but each document in a collection can have a different structure. Relationships are not stored within such collections and hence, joins are not available in the database. Alternatively, a set of documents can be embedded within a document to provide a level of denormalization.
Examples of Document DBs: MongoDB, Couchbase, CouchDB, Google Cloud Firestore and Amazon DocumentDB.
Graph Databases
Graph databases are a type of NoSQL database that takes a different approach to establishing relationships between data. Rather than mapping relationships with tables and foreign keys, graph databases establish connections using the concepts of nodes, edges, and properties. Graph databases represent data as individual nodes which can have any number of properties associated with them. Between these nodes, edges (also called relationships) are established to represent different types of connections. In this way, the database encodes information about the data items within the nodes and information about their relationship in the edges that connect the nodes.
Graph databases can be implemented as a native graph; which means they store data in the graph model described above, while non-native graphs store data in relational or other NoSQL databases and use graph processing engines for data access. Native Graphs implement index-free adjacency for data access.
Examples of Graph DBs: Neo4j, JanusGraph, Amazon Neptune, ArangoDB, Dgraph and Memgraph.
Column-Family Databases
Column-family databases, also called non-relational column stores, wide-column databases, or simply column databases, are perhaps the NoSQL type that, on the surface, looks most similar to relational databases. Like relational databases, wide-column databases store data using concepts like rows and columns. Technically, however, a wide-column store is closer to a two-dimensional key-value store. These databases often support the notion of column families that are stored separately. Each such column family typically contains multiple columns that are used together.
Column-family databases are implemented as multidimensional nested sorted map of maps. The innermost map constitutes a version of the data identified by a timestamp and stored in a cell. A cell is mapped to a column which in turn is mapped to a column family. A set of column families are identified using a row key. Read and write is performed using the row key on sets of columns. These columns are stored as a continuous entry on the disk, enhancing performance and enabling users to access only the specific columns they need without allocating additional memory on irrelevant data.
Examples of Column-family DBs: Cassandra, HBase, Google Cloud Bigtable, ScyllaDB and DataStax.
Time-Series Databases
Time-series databases are data stores that focus on collecting and managing values that change over time. Although sometimes considered a subset of other database types, like key-value stores, time-series databases are prevalent and unique enough to warrant their own consideration. Many time-series databases are organized into structures that record the values for a single item over time (metrics). For example, a table or similar structure could be created to track CPU temperature. Inside, each value would consist of a timestamp and a temperature value to map what the temperature was at specific points in time.
In terms of read and write characteristics, time series databases are heavily write oriented. They are designed to handle a constant influx of incoming data. In general, time series databases work with regular, consistent streams of data without many spikes, which makes it simpler to plan around than some other types of data. Performance often depends on the number of items being tracked, the polling interval between recording new values, and the actual data payload that needs to be saved.
Examples of Time-series DBs: Prometheus, InfluxDB, Timescale, Whisper.
Vector Databases
A vector database is a specialized database storage designed to store, index, and query vector data. In the context of a Vector DB, vector embeddings are lists of numbers that represent patterns of relationships created to represent unstructured data such as images, texts and audio. Vectors capture semantic meaning, so they can be used for relevancy or context based search, rather than simple text search. By utilizing word embeddings, vector databases can better understand the relationships between words and generate more accurate results. Vector databases make it easier for Large Language Models (LLMs) to remember previous inputs, allowing machine learning to be used to power search, recommendations, and text generation use-cases.
Examples of vector DBs: Pinecone, Milvus, Weaviate, and Chroma.
Multi-Model Databases
Multi-model databases are databases that combine the functionality of more than one type of database. The benefits of this approach are clear — the same system can use different representations for different types of data.
Collocating the data from multiple database types in the same system allows for novel operations that would be difficult or impossible otherwise. For instance, multi-model databases may allow users to access and manipulate data stored in different database types within a single query. Multi-model databases also help maintain data consistency, which can be a problem when performing operations that modify data in many systems at once.
Many of the most popular relational databases actually support multi-model, including Oracle, MySQL, PostgreSQL and SQL Server. Other multi-model DBs include Azure Cosmos DB, FaunaDB and SurrealDB.