Computer data storage is a technology consisting of computer components and recording media that are used to retain digital data. It is a core function and fundamental component of computer systems. Users can save data onto a storage device. Computers can read input data from various sources as needed, and it can then create and save the output to the same or other storage locations. Users can also share data storage with others.
Data storage can be described as 3 main facets:
- Devices and media – Storage devices that retain the data in magnetic, optical or mechanical media.
- Topology – Computers connect to storage devices either directly or through a network.
- Data model – Data is organized and stored in various formats such as files, blocks and objects.
Storage Devices
In the physical layer, there are various types of storage devices that are used by modern computers:
- Hard Disk Drive (HDD) – an electro-mechanical device that stores and retrieves digital data using magnetic storage with one or more rigid rapidly rotating platters coated with magnetic material.
- Solid State Drive (SDD) – a solid-state device that uses integrated circuit assemblies to store data persistently, typically using flash memory.
- Optical Disc Drive – a device that uses laser light or electromagnetic waves within or near the visible light spectrum as part of the process of reading or writing data to or from different types of optical discs, such as CD, DVD and Blue-Ray.
- Magnetic Tape Drive – a device that reads and writes data on a magnetic tape using digital recording.
Storage Topologies
The 3 most prevalent topologies for connecting computers and storage devices are:
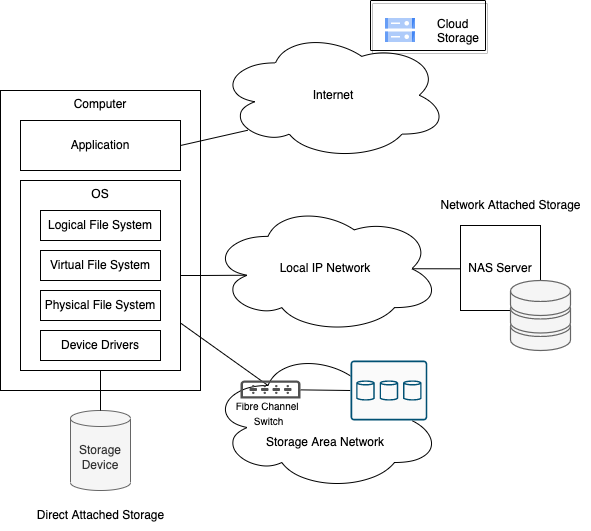
- Direct Attached Storage (DAS) – a storage device that is directly connected to the computer system through an internal or external cable (USB, SATA, SAS, etc.). DAS can hold multiple storage drives in a single enclosure, which is directly connected to the machine through a Host Bus Adapter (HBA).
- Network Attached Storage (NAS) – a file-level data storage server connected to a computer network. It provides storage and access to data from a central location to several authorized network users and other groups of clients. Most NAS devices come as multi-device (SSD/HDD) enclosures. The disks in a NAS are typically combined using a redundancy solution like a redundant array of independent disks (RAID). NAS solutions use networking protocols such as Network File System (NFS) or Server Message Block (SMB) / Common Internet File System (CIFS) to provide connectivity across the network.
- Storage Area Network (SAN) – a high-performance, dedicated storage network that provides distributed block-level access to host devices. SAN provides the performance of a DAS with the flexibility of the NAS yet with significantly increased configuration and maintenance complexity. SAN typically uses protocols such as SCSI, iSCSI, and Fibre Channel to facilitate connectivity between the hosts and the storage devices.
Cloud storage does not refer to a specific technology or topology. It is a cloud computing model that enables storing data and files on the Internet through a cloud provider that can be accessed either through the public internet or a dedicated private network connection. The provider securely stores, manages, and maintains the storage servers, infrastructure, and network to ensure users have access to the data when they need it at virtually unlimited scale, and with elastic capacity. When using cloud storage services, the user is aware of the storage format and performance, but usually doesn’t care about the underlying topology.
Storage Topologies
Storage Formats
Files, blocks, and objects are storage formats that hold, organize, and present data in different models — each with their own capabilities and limitations. File storage organizes and represents data as a hierarchy of files in folders; block storage chunks data into arbitrarily organized, evenly sized pieces; and object storage manages data and links it to associated metadata.
File Storage
File storage, also called file-level or file-based storage, is the oldest and most widely used data storage system for direct and network-attached storage systems. It is based on a file system (FS), which is a method and data structure that the operating system (OS) uses to control how persistent data is organized, stored and retrieved. The data is easily isolated and identified by separating it into pieces and giving each piece a name. Each piece is called a file, which is stored as a single unit of information inside a folder. Folders are organized under a hierarchy of directories and subdirectories. When a user or a program needs to access that piece of data, the OS needs to know the path to find it. Data stored in files is organized and retrieved using a limited amount of metadata that tells the OS exactly where the file itself is kept.
File System
A file system defines how files are named, stored and retrieved from a storage device. There are many kinds of file systems (e.g., FAT, NTFS, exFAT, Ext, HFS, etc.), each with unique structure and logic, properties of speed, flexibility, security, size and more. The most basic file systems are used on local (directly attached) data storage devices, but a FS can also provide remote file access via network protocols (such as NFS or SMB/CIFS).
A file system installed on an operating system consists of three layers:
- Logical file system – the user-facing part of a file system, which provides an API to enable user programs to perform various file operations, such as OPEN, READ and WRITE, without having to deal with any storage hardware directly.
- Virtual file system (VFS) – provides a consistent view of various file systems mounted on the same OS. It serves as a bridge between the logical layer (which programs interact with) and a set of the physical layer of various file systems.
- Physical file system – the concrete implementation of a file system; It’s responsible for data storage and retrieval and space management on the storage device (or precisely: partitions). The physical FS interacts with the storage hardware via device drivers.
In the physical layer, storage is linear space for reading or both reading and writing digital information. Each byte of information on it has its offset from the storage start, known as an address and is referenced by this address. A storage can be presented as a grid with a set of numbered cells (each cell is a single byte). Any item saved to the storage gets its own cells. Generally, computer storages use the pair of a sector and in-sector offset to reference any byte of information on the storage. But in most cases, it operates in blocks, which are groups of sectors that optimize storage addressing. Modern types generally use block sizes from 1 to 128 sectors (512-65536 bytes). Files are usually stored at the start of a block and take up entire blocks.
Storage devices must be partitioned and formatted before the first use. Partitioning means splitting a storage device into several logical regions, so they can be managed separately as if they are separate storage devices. A storage device should have at least one partition. Usually there is one partition dedicated to the OS, another one for the users’ files and an optional swap partition (works as the RAM extension when it runs out of space). Windows OS assigns a drive letter (A, B, C, etc.) to each partition or removable storage device. In Unix-like operating systems, partitions appear as ordinary directories under the root directory. The act of assigning a directory to a storage device (under the root directory tree) is called mounting, and the assigned directory is called a mount point.
Block Storage
Block storage, sometimes referred to as block-level storage, is a technology that is used to store data files on Storage Area Networks (SANs) or cloud-based storage environments. Block storage breaks up data into fixed-size blocks and then stores those blocks as separate chunks, each with a unique identifier. Each block lives on its own and can be partitioned so it can be accessed in a different OS.
Block storage is often configured to decouple the data from the user’s environment and spread it across multiple environments that can better serve the data (wherever it is most efficient). When data is requested, the underlying storage software reassembles the blocks of data from these environments and presents them back to the user. Block storage is considered a highly efficient storage system because storing and retrieving data is not dependent on the user OS. The SAN identifies the connected blocks through indexing and puts them together to retrieve the data in its original form. Because block storage doesn’t rely on a single path to data (like file storage does), it can be retrieved quickly with low latency.
Object Storage
Object storage, also known as object-based storage, is a data storage that manages unstructured data as objects, as opposed to files or blocks. Each object typically includes the data itself, a variable amount of metadata, and a globally unique identifier. These objects are stored in a single, structurally flat logical repository, which can be spread out across multiple networked systems.
In practice, applications manage all of the objects, eliminating the need for a traditional file system. Each object receives a unique ID, which applications use to identify the object. Each object stores also metadata — information about the data stored in the object. Metadata includes details like age, privacies/securities, and access contingencies, and can be customized to include additional, detailed information about the data files stored in the object.
Unlike file storage and block storage, object storage is not handled as a logical file system and is not governed by the OS. Objects in an object storage system are accessed via Application Programming Interfaces (APIs). The native API for object storage is an HTTP-based RESTful API. These APIs query an object’s metadata to locate and access the desired object (data) via the Internet from anywhere, on any device. The most common Object storage API is based on Amazon Simple Storage Service (S3), which is widely adopted by various vendors that offer S3-compatible object storage.